A amostragem por rejeição é uma técnica útil para gerar variáveis aleatórias de uma distribuição de probabilidade complexa a partir de uma distribuição proposta mais simples. A ideia básica é simular de uma distribuição discreta fácil de amostrar e, em seguida, rejeitar ou aceitar essas amostras com base na distribuição alvo.
7.1 Algoritmo
Seja \(X\) uma variável aleatória tal que \(P(X = x_j) = p_j\). O método da rejeição assume que sabemos simular valores de uma segunda variável aleatória \(Y\), cuja distribuição cubra todo o suporte de \(X\). Seja \(q_j = P(Y = x_j)\); essa distribuição é chamada de distribuição proposta.
Além disso, assume-se que existe uma constante \(c\) tal que:
\[
\frac{p_j}{q_j} \leq c \quad \text{para todo } j \text{ com } p_j > 0,
\]
e que essa constante pode ser calculada.
O algoritmo do método da rejeição segue os seguintes passos:
Gere um valor \(Y\) a partir da distribuição proposta \(q_j\).
Gere\(U \sim \text{Uniform}(0,1)\), independente de \(Y\) gerado.
Aceite\(Y\) se \[
U \leq \frac{P(X=y)}{c \cdot P(Y=y)};
\] caso contrário, rejeite\(y\) e repita o processo.
7.2 Exemplo
Vamos exemplificar a amostragem por rejeição gerando amostras de uma distribuição alvo discreta \(p_j\), utilizando uma distribuição uniforme discreta como distribuição proposta.
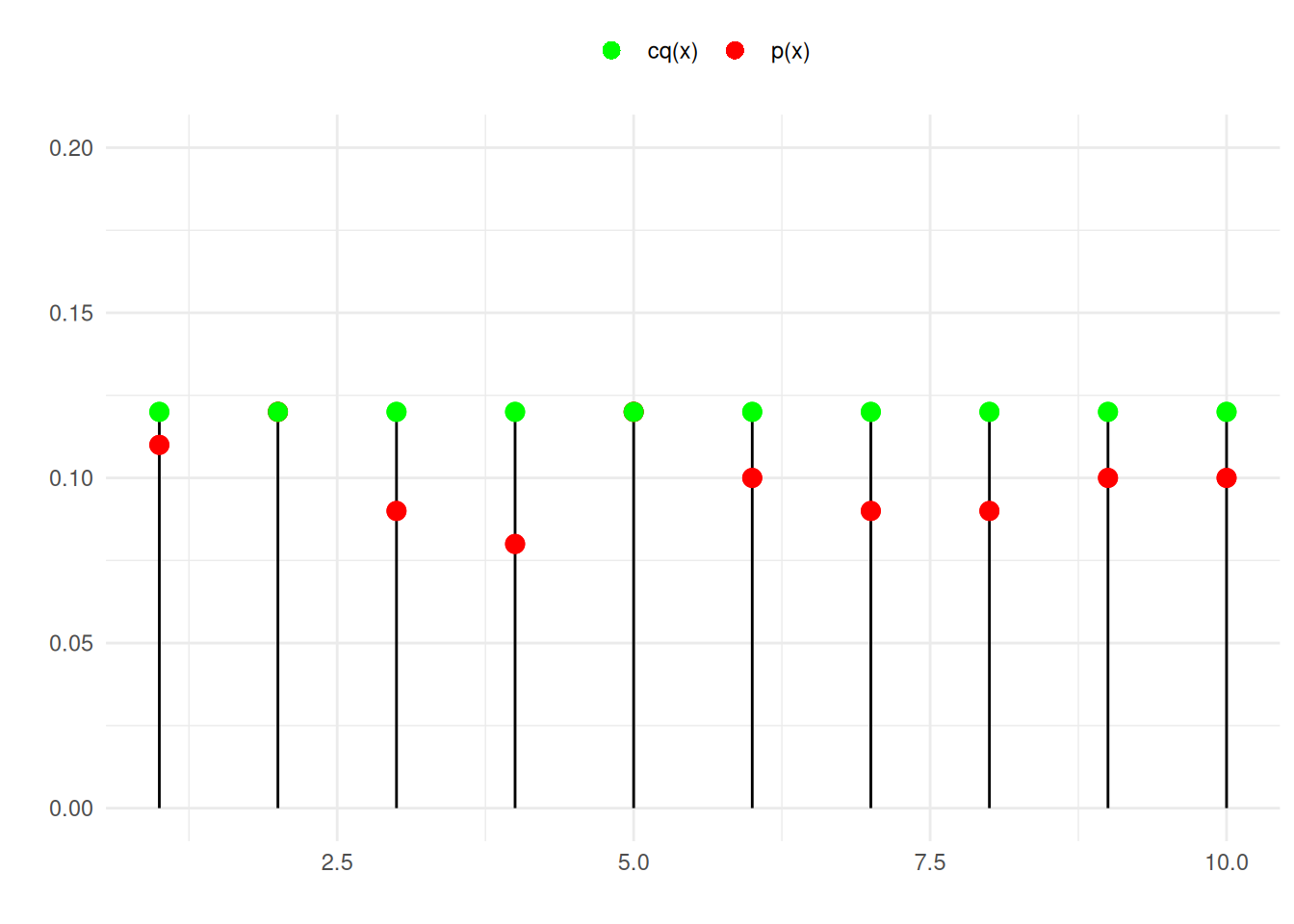
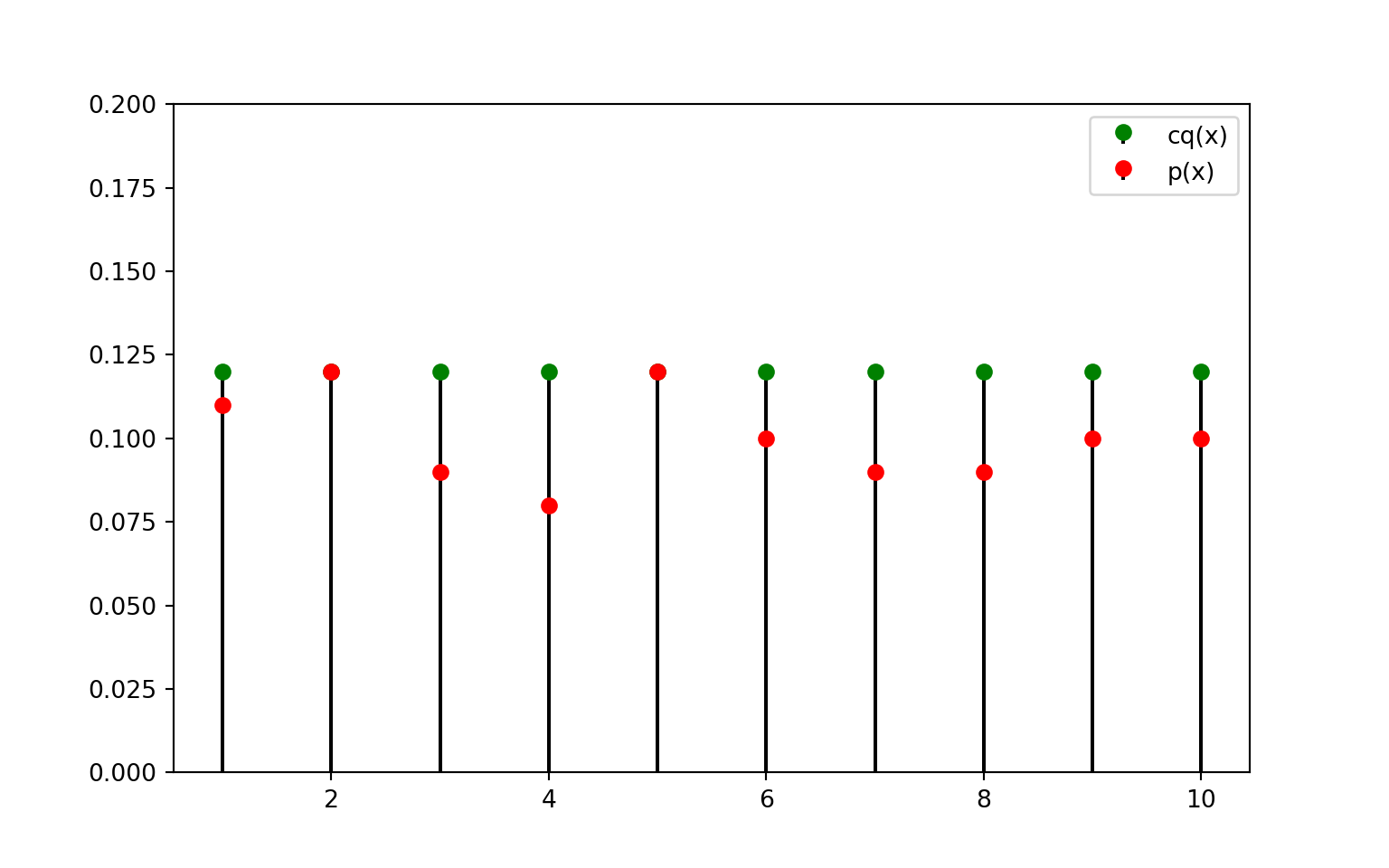
Suponha que \(Y\) siga uma distribuição uniforme discreta em \(\{1, 2, \dots, 10\}\), ou seja, \(q_j = 1/10\) para todos os valores \(j\). A distribuição alvo \(p_j\) tem os seguintes valores:
\(j\)
1
2
3
4
5
6
7
8
9
10
\(p_j\)
0.11
0.12
0.09
0.08
0.12
0.10
0.09
0.09
0.10
0.10
Para aplicar o método de aceitação e rejeição, precisamos de uma constante \(c\) tal que \(\frac{p_j}{q_j} \leq c\) para todo \(j\). Neste caso, temos \(c = 1.2\).
A seguir, ilustramos o método da rejeição para esse problema. Amostramos um dos números do suporte, 1, …, 10, com probabilidade uniforme. A seguir, aceitamos esse número com probabilidade proporcional à área abaixo do ponto vermelho (em relação à área abaixo do ponto verde).
# --- Parâmetros definidos no problema ---# Valores de j (suporte da distribuição)j_values <-1:10# Distribuição alvo p_jp_j <-c(0.11, 0.12, 0.09, 0.08, 0.12, 0.10, 0.09, 0.09, 0.10, 0.10)# Distribuição proposta q_j (Uniforme Discreta)q_j <-rep(1/10, 10)# Constante c tal que p_j <= c * q_jc <-max(p_j / q_j)# Número de amostras desejadasn_samples <-1000# Vetor para armazenar as amostras aceitasaccepted_samples <-c()# --- Implementação do Método da Rejeição ---# Para facilitar a busca, nomeamos o vetor p_j com os valores correspondentes de jnames(p_j) <- j_values# Para a distribuição uniforme q_j, o valor é sempre 1/10q_val <-1/10# Loop até que o número desejado de amostras seja geradowhile (length(accepted_samples) < n_samples) {# 1. Gere um valor Y a partir da distribuição proposta q_j# Como q_j é uniforme, usamos a função sample() para escolher um valor de j_values y <-sample(j_values, 1)# 2. Gere U ~ Uniform(0,1) u <-runif(1)# 3. Teste de aceitação# Acessamos p(y) usando o nome do vetor (convertendo y para caractere para busca) acceptance_ratio <- p_j[as.character(y)] / (c * q_val)if (u <= acceptance_ratio) {# Se aceito, adicione o valor ao vetor de amostras accepted_samples <-c(accepted_samples, y) }}# --- Exibição dos Resultados ---cat("\nAs primeiras 20 amostras geradas são:\n")
As primeiras 20 amostras geradas são:
Mostrar código
print(head(accepted_samples, 20))
[1] 6 8 8 5 3 3 6 5 9 6 3 9 10 4 7 5 7 1 8 2
Mostrar código
# Criação da tabela de frequênciafreq_table <-table(factor(accepted_samples, levels = j_values))relative_freq <-prop.table(freq_table)# Montamos um data.frame final para exibir os resultadosresults_df <-data.frame(`Valor (j)`=as.integer(names(freq_table)),`Frequência Absoluta`=as.integer(freq_table),`Frequência Relativa (Observada)`=as.numeric(relative_freq),`Probabilidade Teórica (p_j)`= p_j,check.names =FALSE)cat("Tabela de Frequência dos 1000 valores gerados:\n\n")
import numpy as npimport pandas as pd# --- Parâmetros definidos no problema ---# Valores de j (suporte da distribuição)j_values = np.arange(1, 11)# Distribuição alvo p_jp_j = np.array([0.11, 0.12, 0.09, 0.08, 0.12, 0.10, 0.09, 0.09, 0.10, 0.10])# Distribuição proposta q_j (Uniforme Discreta)q_j = np.full_like(p_j, 1/10)# Constante c tal que p_j <= c * q_jc =max(p_j / q_j)# Número de amostras desejadasn_samples =1000# Lista para armazenar as amostras aceitasaccepted_samples = []# --- Implementação do Método da Rejeição ---# Para facilitar, criamos um dicionário que mapeia cada valor j à sua probabilidade p_jp_map = {j: p for j, p inzip(j_values, p_j)}# Para a distribuição uniforme q_j, a probabilidade é sempre 1/10q_val =1/10# Loop até que o número desejado de amostras seja geradowhilelen(accepted_samples) < n_samples:# 1. Gere um valor Y a partir da distribuição proposta q_j# Como q_j é uniforme em {1, ..., 10}, podemos simplesmente escolher um inteiro nesse intervalo. y = np.random.choice(j_values)# 2. Gere U ~ Uniform(0,1) u = np.random.rand()# 3. Teste de aceitação# Calculamos a razão p(y) / (c * q(y)) acceptance_ratio = p_map[y] / (c * q_val)if u <= acceptance_ratio:# Se o teste passar, aceitamos o valor e o adicionamos à nossa lista accepted_samples.append(y)# --- Exibição dos Resultados ---print("\nAs primeiras 20 amostras geradas são:")
# Criação da tabela de frequência usando a biblioteca pandassamples_series = pd.Series(accepted_samples)# value_counts() conta a ocorrência de cada valor. sort_index() ordena pelos valores de j.freq_table = samples_series.value_counts().sort_index()# Calculamos a frequência relativa (proporção) para comparar com p_jrelative_freq = freq_table / n_samples# Montamos um DataFrame final para exibir os resultadosresults_df = pd.DataFrame({'Valor (j)': freq_table.index,'Frequência Absoluta': freq_table.values,'Frequência Relativa (Observada)': relative_freq.values,'Probabilidade Teórica (p_j)': p_j})print("Tabela de Frequência dos 1000 valores gerados:\n")
Tabela de Frequência dos 1000 valores gerados:
Mostrar código
# Usamos to_string() para garantir que a tabela seja bem formatadaprint(results_df.to_string(index=False))
Teorema: O método da aceitação e rejeição gera uma v.a. X tal que
\[
P(X = x_j) = p_j ,\ j = 0, 1, \dots
\]
Além disso, o número de passos que o algoritmo necessita para gerar X tem distribuição geométrica com média c.
Prova:
Seja \(Y\) um valor proposto pelo método no passo 1. Temos que
\[
P(Y = x_j \text{ e aceitar o valor proposto}) = P(Y = x_j)P(\text{aceitar o valor proposto} | Y = x_j) = q_j
\frac{p_j}{c q_j} = \frac{p_j}{c}
\]
Então,
\[
P(\text{aceitar o valor proposto}) = \sum_{j=0}^{\infty} \frac{p_j}{c} = \frac{1}{c}
\]
A cada passo a probabilidade de aceitar um valor é \(\frac{1}{c}\), então o número de passos necessários para aceitar um valor tem distribuição geométrica com média c.
Além disso, temos
\[
P(X = x_j) = \sum_{n=1}^{\infty} P(text{aceitar pela 1a vez no passo n e }Y = x_j) = \sum_{n=1}^{\infty} \left(1 - \frac{1}{c}\right)^{n-1} \frac{p_j}{c} = p_j
\]
7.3 Exercício
Exercício 1.
Suponha uma distribuição alvo \(X\) com suporte em \(\{1, 2, \dots, 15\}\) e função de probabilidade definida por: \[p_j = \frac{\ln(j+1)}{\sum_{k=1}^{15} \ln(k+1)}, \quad j = 1, 2, \dots, 15.\] Use como distribuição proposta uma uniforme discreta em \(\{1, 2, \dots, 15\}\). Determine a constante \(c\), implemente o método da rejeição e gere 1000 amostras. Analise a eficiência do método calculando a taxa de aceitação esperada e comparando com o valor teórico \(1/c\).
Exercício 2.
Neste exercício, o desafio é amostrar de uma distribuição com suporte infinito, a distribuição de Poisson, mas com uma restrição: não queremos incluir o valor zero. Isso é útil em cenários onde contamos eventos, mas apenas os casos em que pelo menos um evento ocorreu são registrados.
A distribuição alvo \(X\) é uma Poisson com parâmetro \(\lambda = 4\), truncada em zero. Sua função de massa de probabilidade (PMF) para \(k \in {1, 2, 3, \dots}\) é:
Como distribuição proposta \(Y\), vamos usar uma distribuição Geométrica com parâmetro \(p=0.25\), que também tem suporte em \(k \in {1, 2, 3, \dots}\). Sua PMF é:
\[q_k = P(Y=k) = (1-p)^{k-1}p\]
Sua tarefa:
Implementar as PMFs: Crie funções em R ou Python que calculem \(p_k\) (Poisson Truncada com \(\lambda=4\)) e \(q_k\) (Geométrica com \(p=0.25\)) para um dado valor de \(k\).
Encontrar a constante c: Ao contrário do exemplo com suporte finito, não podemos simplesmente dividir \(p_j/q_j\) para todos os valores. Para aproximar o máximo (que não tem solução analítico), podemos fazer o seguinte:
Calcule a razão \(r_k = p_k / q_k\) para um intervalo razoável de valores (ex: de \(k=1\) a \(k=\lceil 10*\lambda \rceil\)).
Faça um gráfico de \(r_k\) em função de \(k\). O valor máximo observado no gráfico será uma excelente aproximação para a constante \(c\).
Implementar o Amostrador:
Escreva o código para o método da rejeição. O passo 1 (gerar \(Y\)) agora envolve amostrar de uma distribuição Geométrica. A maioria das linguagens de programação possui uma função para isso (por exemplo, rgeom em R com um ajuste, ou numpy.random.geometric em Python).
Gere um total de 5000 amostras da distribuição de Poisson Truncada.
Validar os Resultados:
Calcule a frequência relativa de cada valor gerado em sua amostra.
Crie um gráfico de barras comparando as frequências relativas observadas com as probabilidades teóricas \(p_k\) da distribuição alvo. Os resultados devem ser bastante próximos, validando sua implementação.