Rafael Izbicki
Rafael Izbicki
Home
Featured Publications
Lecture Notes
Teaching
Talks
Posts
Students
Contact
Miscellanea
Light
Dark
Automatic
Machine Learning
Hierarchical clustering: visualization, feature importance and model selection
We propose methods for the analysis of hierarchical clustering that fully use the multi-resolution structure provided by a dendrogram. …
L. M. C. Cabezas
,
Rafael Izbicki
,
R. B. Stern
February, 2023
Applied Soft Computing Journal
Preprint
Simulation-Based Inference with Waldo: Confidence Regions by Leveraging Prediction Algorithms or Posterior Estimators for Inverse Problems
L. Masserano
,
T. Dorigo
,
Rafael Izbicki
,
M. Kuusela
,
A. B. Lee
February, 2023
Proceedings of Machine Learning Research (AISTATS track; Finalist at the ASA SPES and Q&P Student Paper Competition)
Preprint
PDF
Quantifying uncertainty in land-use land-cover classification using conformal statistics
D. Valle
,
Rafael Izbicki
,
R. Leite
February, 2023
Remote Sensing of Environment
NLS: An accurate and yet easy-to-interpret prediction method
Over the last years, the predictive power of supervised machine learning (ML) has undergone impressive advances, achieving the status …
V. Coscrato
,
M. H. A. Inacio
,
T. Botari
,
Rafael Izbicki
January, 2023
Neural Networks
Preprint
PDF
A new LDA formulation with covariates
G. Shimizu
,
Rafael Izbicki
,
D. Valle
January, 2023
Communications in Statistics - Simulation and Computation
Preprint
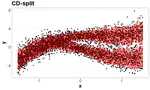
CD-split and HPD-split: Efficient conformal regions in high dimensions
Conformal methods create prediction bands that control average coverage assuming solely i.i.d. data. We introduce CD-split and HPD-split, which yield general prediction regions and converge to the optimal highest predictive density set.
Rafael Izbicki
,
Gilson Shimizu
,
Rafael B. Stern
May, 2022
Journal of Machine Learning Research
PDF
Cite
Code
Likelihood-Free Frequentist Inference: Confidence Sets with Correct Conditional Coverage
Many areas of science make extensive use of computer simulators that implicitly encode likelihood functions of complex systems. …
N. Dalmasso
,
L. Masserano
,
D. Zhao
,
Rafael Izbicki
,
A. B. Lee
April, 2022
Submitted
PDF
Causas de desaparecimento no estado de São Paulo entre 2013 e 2014: uma análise automatizada de boletins de ocorrência
Este artigo estuda as causas de desaparecimento no estado de São Paulo por idade e sexo dos desaparecidos. Para tanto, utiliza algoritmos de aprendizado de máquina para avaliar automaticamente o texto de boletins de ocorrência.
Mateus B. Comito
,
Rafael Izbicki
,
Rafael B. Stern
,
Julio A. Z. Trecenti
February, 2021
In
RDPESP
PDF
Cite
Identifying Distributional Differences in Convective Evolution Prior to Rapid Intensification in Tropical Cyclones
Tropical cyclone (TC) intensity forecasts are issued by human forecasters who evaluate spatio-temporal observations (e.g., satellite …
T. McNeely
,
G. Vincent
,
Rafael Izbicki
,
K. M. Wood
,
A. B. Lee
February, 2021
Tackling Climate Change with Machine Learning workshop at NeurIPS 2021 (poster)
PDF
The Latent Dirichlet Allocation model with covariates (LDAcov): a case study on the effect of fire on species composition in Amazonian forests
Understanding and predicting the effect of global change phenomena on biodiversity is challenging given that biodiversity data are …
D. Valle
,
G. Shimizu
,
Rafael Izbicki
,
L. Maracahipes
,
D. Silvério
,
L. Paolucci
,
Y. Jameel
,
P. Brando
February, 2021
Ecology and Evolution
PDF
«
»
Cite
×